Cynthia Merle Coupé Audo
B.A. San Francisco State University, 2002
M.A. University of Colorado, 2004
|
 |
Reproduced with the permission of the author.
A thesis submitted to the faculty of the Department of Speech and Hearing Sciences in partial fulfillment of the requirements for the degree of Speech and Language Pathology, Department of Speech and Hearing Sciences, 2004
Thesis directed by Dr. Lorraine Olson Ramig
|
Purpose:
Children with Down syndrome have speech and voice disorders which may limit functional communication and contribute to a decreased quality of life. The data on speech treatment approaches for this population remains limited. Although speech intelligibility has been documented as a major component of the communication problems in children with Down syndrome, there is yet to be a successful intervention program designed to target these needs.
The purpose of this thesis was to apply LSVT® to one individual with Down syndrome in order to evaluate whether speech and voice characteristics can be improved using this type of therapy. LSVT® has been proven to improve voice quality and general oral-motor function in the Idiopathic Parkinson's Disease (IPD) population. Many of the difficulties experienced by children with Down syndrome parallel the difficulties experienced by individuals with IPD.
Method:
A multiple baseline, single-subject design with control was used. Acoustic measures consisted of auditory-perceptual analysis of speech samples and timed length of phonation samples. Treatment perceptions by the parents of participants in this study were obtained from baseline and post-treatment recording sessions.
Results:
The participant who received treatment demonstrated a marked change in phonation length and improved phonation quality. There were strong listener preferences for the post-treatment speech samples. Additionally, the parent of the treated participant reported improved perceptions on several measures of speech and voice characteristics and reported an overall favorable impression of their child's treatment outcome. The participant who did not receive treatment showed no improvement from pre to post sessions on any of the variables measured.
Conclusion:
These findings suggest that intensive speech treatment was beneficial in changing the speech and motor output for the experimental subject with Down syndrome. Listeners preferred the post speech samples over baseline speech samples, suggesting that this intervention may be beneficial for the Down syndrome population. These findings have the potential to generate pilot data to support future research which will enhance the current method of speech treatment for people with Down syndrome, thereby significantly improving the speech outcome for this population.
In memory of my father, James Albert Coupé Sr.
September 7th, 1933—July 2nd, 2003
You instilled in me the importance of a strong work ethic which helped me get where I am today.
For this I am eternally grateful.
Thank you.
I will always love you.
I would first and foremost like to acknowledge, appreciate and applaud my wonderful husband, Carl Vincent Audo, for being by my side. You make even the dark days bright. 8:27
Great amounts of gratitude to my wonderful momma, Brenda Harney, who, among other things, bestowed me with the gift of writing.
A special thanks to Tara Robinson. Without your help there is no way I would have gotten this done! Thank you again and again...
To the listeners who rated these samples: Thank you kindly. Your ratings made this possible.
To my thesis committee: Thank you for your patience, edits and advice. You are a fantastic group of faculty.
To my thesis mentor: Dr. Lorraine Olson Ramig. You have an amazing ability to make things happen—you're on the Gas! Thank you.
To everyone who helped out with this project in some form or another; whether you found research articles, took on-line data, or recorded at NCVS you helped immeasurably. Thank you.
Most of all, I would like to offer a huge thank you to the participants and their families. I learned so much from doing this project, and I really think it can make a difference. Thank you for responding to my ad!
Last but certainly not least I would like to give a world of thanks to the Coleman Foundation for funding this project. This is only the beginning. Thank you for helping us start.
TABLE OF CONTENTS
ABSTRACT
DEDICATION
ACKNOWLEDGEMENTS
- INTRODUCTION
- Overview of Down syndrome
- Speech Development in Children with Down syndrome
- Treatment for Speech
- METHOD
- Participants
- Subject 1 (S1)
- Subject 2 (S2)
- Design
- Procedures
- Participant Selection
- Study Conditions
- Experimental Subject (S1)
- Control Subject (S2)
- Recording Sessions
- Equipment and Set-up
- Interviews
- Treatment Rating Forms
- Speech and Voice Tasks
- Data Collectors
- Intensive Voice Treatment
- Data Analysis
- Data Preparation and Digitizing Procedures
- Acoustic Analysis
- Sustained Phonation
- Auditory-Perceptual Analysis (Investigator)
- Auditory-Perceptual Analysis (Listener Task)
- Analysis of Parent Perceptual Ratings
- Determination of Treatment Effects
- RESULTS
- Data for S1
- Sustained Phonation (3 longest vowels)
- Investigator Ratings
- Goldman Fristoe Test of Articulation
- Intelligibility Sentences
- Picture Description
- Listener Ratings
- Functional Communication
- Voice Quality
- Parent Rating Forms
- Summary of Results for S1
- Data for S2
- Sustained Phonation (3 longest vowels)
- Listener Ratings
- Functional Communication
- Articulation
- Voice Quality
- Parent Perceptual Ratings
- Summary of Results for S2
- DISCUSSION
- Changes in the Speech System
- Evidence of a Therapeutic Effect
- General Comments on the Treatment Model
- Study Critiques and Future Directions
- Summary and Conclusions
BIBLIOGRAPHY
- LIST OF FIGURES
- Figure 1. Pre and Post comparison for S1's 3 longest sustained "ah's"
- Figure 2. Pre and Post comparison for S2's 3 longest sustained "ah's"
- Figure 3. Comparison charts of S1's pre and post voice measures for the GFTA
- Figure 4. Comparison charts of S1's pre and post voice measures for the intelligibility sentences
- Figure 5. Comparison charts of S1's pre and post voice measures for the Picture description
- Figure 6. table 1 (S1), table 2 (S2). Percentage of listener ratings for "Functional Communication" on the Goldman Fristoe Test of Articulation (GFTA)
- Figure 7. table 1 (S1) and table 2 (S2). Percentage of listener ratings for "Functional Communication" on the picture description task
- Figure 8. table 1 (S1), table 2 (S2). Percentage of listener ratings for "Articulation" on the GFTA
- Figure 9. table 1 (S1), table 2 (S2). Percentage of listener ratings for "Articulation" on the picture description task
- Figure 10. table 1 (S1), table 2 (S2). Percentage of listener preference for "Voice Quality" on the GFTA
- Figure 11. table 1 (S1), table 2 (S2). Percentage of listener preference for "Voice Quality" on the picture description task
- Figure 12. table 1 (S1), table 2 (S2). Percentage of listener preference for "Voice Quality" on the sustained "ah" task
- Figure 13. Treatment Rating Form: S1 parent post survey
- Figure 14. Treatment Rating Form: S2 parent post survey
- LIST OF APPENDICES
-
- Recruiting Advertisement
- Screening Questionnaire for Potential Participants
- Voice Recording Protocol
- Initial Interview—Parent
- Parental Post Treatment Questions
- Treatment Rating Form
- Maximum Duration Sustained Vowel Phonation "Ah"
- Maximum Frequency Range
- Daidokokinetics
- Intelligibility Sentences
- Intelligibility Words
- Picture Description
- Daily LSVT® Tasks and Treatment Forms
- Homework Form
- General Information Sheet—Listener Ratings
- Listener Task—Articulation
- Listener Task—Voice Quality
- Listener Task—Functional Communication
Overview of Down syndrome
Down syndrome is a chromosomal disorder caused by the presence of three copies of the 21st chromosome rather than the typical two (Batshaw, 2002). Down syndrome is the most prevalent chromosomal abnormality occuring in approximately one in every 800 live births (Batshaw, 2002). Individuals with Down syndrome have several distinguishing features including a short stature, flat facial profile, hypoglossia, hypotonia, hyperextendable joints and cognitive delays that vary from mild to severe. (Miller and Leddy, 1998)
A distinctive characteristic that separates the Down syndrome population from the non-Down syndrome population is that of voice quality (Montague, Brown & Hollien, 1974). The vocal quality of individuals with Down syndrome has been described as breathy, husky, harsh, monotonous, raucous, perceptually lower pitched and more acoustically variable (West, Ansberry & Carr, 1957; Benda, 1969: Jung, J.H., 1989; Pentz and Gilbert, 1983). Furthermore, individuals with Down syndrome are hypotonic (low muscle tone) and have been described as having hypoglossia (increased tongue size) in combination with reduced orofacial muscle tone which results in feeding, sucking and swallowing difficulties, as well as dysfunction of the lips, tongue and jaw (Batshaw, 2002; Spender, Stein, Cave, Reilley & Reilly, 1995). According to Hamilton (1993) individuals with Down syndrome have "difficulties with coordinating the rapid tongue movements necessary for clear speech" (p 15). Research has shown that children with Down syndrome exhibit severe, harsh and monotone voice characteristics (Pentz and Gilbert, 1983). In addition, children with Down syndrome appear to be perceived more negatively due to these abnormal vocal qualities (Moran, LaBarge & Haynes, 1988). In terms of self confidence, such negative perceptions may have a far reaching impact on the self confidence level of children with Down syndrome.
Speech Development in Children with Down Syndrome
In a study by Kumin (1994) titled: "Intelligibility of Speech in Children with Down syndrome in Natural Settings: Parents' Perspective" results showed that over 95% of the children were reported to have some difficulty being understood. Of these, between 48-72% had difficulty in sequencing sounds, 80% had difficulty with articulation, 49% had difficulty with rate of speaking and 13% had difficulty with voice. Indeed, earlier studies (, 1964; Schlanger & Gottsleben, 1957) had found that 95-100% of children with Down syndrome have deviant articulation, and later studies (Dodd 1976; Rosin, Swift, Bless, Vetter, 1988) support these findings. Research has also supported the fact that individuals with Down syndrome take much longer to develop clear speech than do age matched peers, and intelligibility increases with chronological age (Miller & Leddy, 1999; Chapman, Schwartz & Bird, 1991).
Miller and Leddy (1998) maintain that intelligibility problems in the Down syndrome population are due to biological speech factors such as variations in the skeletal, muscular, and nervous systems. These authors contend that skeletal variations in the head and face such as a smaller skull, poorly developed midfacial bones, and a smaller, wider mandible may contribute to a reduced oral cavity and pharynx which results in decreased resonation for speech. Muscular system differences in the Down syndrome population result in additional and missing muscles throughout their bodies as well as an increased tongue size. Anomalies in the nervous system of these individuals likely impacts the sequencing and timing of the movements needed for speech. (Leddy, 1999 as cited in Miller, Leddy, Leavitt, 1999). As Leddy (1999) states: "These anatomical differences may affect speech production, probably disrupting the accuracy, speed, consistency, and economy of their speech movements and thus altering the sequencing and timing of their speech" (p 74). In terms of language, studies by Chapman, 1995; Miller, 1987, 1988; and Miller, Rosin, Pierce, Miolo & Sedey,1989 (as cited in Miller, 1999); Miller, Striet, Salmon & Lafolette, 1987 (as cited in Miller, 1999) conclude that individuals with Down syndrome also have a Specific Language Impairment (SLI) where their comprehension of language exceeds their production of language.
Together, research has found that the language and speech profile of individuals with Down syndrome include poor intelligibility, SLI (better language comprehension than production) and vocabulary that exceeds grammar use (Chapman, 1997; Fowler 1995; Miller 1988; Miller, Leddy, Milolo & Sedey, 1995). Progress in speech and language production appears to be related to hearing status, speech motor function, nonverbal cognitive level and chronological age. Language therapy that continues into late adolescence is beneficial for the Down syndrome population with increases in comprehension, production, and speech intelligibility (Buckley, 1993; Cossu, Rossini & Marshall, 1993; Shepperdson, 1994; Ledy & Gill, 1999).
Treatment for Speech
Although speech production is a known issue for this population, previous research points mainly to language therapy rather than speech or voice therapy for individuals with Down syndrome. A study by Pryce (1994) confirms that due to the poor articulatory abilities of this population intervention should begin early in life with more emphasis on initiating voice increasing and vocal efficiency. In terms of intervention, Rosin and Swift (1999) state that "as of 1999 there are no intervention programs or guidelines to assist speech-language pathologists in developing integrated approaches to meet both the speech intelligibility and language communication needs of this population" (p 133). Speech intelligibility has been documented as a major component of the communication problems in children with Down syndrome, yet there is currently no successful intervention program designed to specifically target speech or voice. As Rosin and Swift (1999) state: "remediation has focused primarily on language and cognitive stimulation" (p 133). Leddy and Gill (1999) shared some techniques they have used for improving speech intelligibility of adults with Down syndrome. These techniques include:
...identifying the person's difficulty and using the person's words to cue him or her to speak more clearly. Instruction examples include the following: ‘Change your talking,' ‘Speak clearly,' Use all your words,' and ‘Say it so I can understand you.' In addition, teach skills to reduce the person's speaking rate or rate bursts, and, if articulation is a focus of the intervention, use a general approach that is not speech sound specific. For example, instruct the person to open his or her mouth more when he or she is speaking. (p 207-208).
An intensive voice treatment model has been developed for use with the Parkinson's population. This treatment model is called the Lee Silverman Voice Treatment (LSVT®) and includes vocal strength training, repeated practice trials, intensive treatment and sensory awareness. LSVT® has been documented as efficacious for the Parkinson's population (Ramig, Countryman, Horii and Thompson, 1995). For individuals with Idiopathic Parkinson's Disease (IPD), the LSVT® method has been proven to increase vocal quality, vocal loudness, and vocal fold closure; improve coordination of the structures used for speech, increase the duration of sustained vowel phonation as well as the maximum range of fundamental frequency and articulatory function (Fox, Morrison and Ramig, 2002). The LSVT® method includes a) a specific focus on voice (effortful and loud production), b) increased effortful production with multiple repetitions, c) intensive treatment (one hour four times a week for four weeks), d) sensory awareness and e) quantification of behaviors (Ramig, Pawalas, et al., 1995).
Similar to the Down syndrome intervention suggestions posed by Leddy and Gill (1999), the Lee Silverman Voice Treatment (LSVT®) is designed to target the same goals, only in a more simplistic fashion and for a different population. Rather than instructing the client to "speak clearly," "use all your words," "change your talking," "open your mouth," or "say it so I can understand you" the LSVT® method consists of a series of daily tasks where the clinician instructs the client to "speak loud" while completing the LSVT® hierarchy (Ramig and Fox, 2003). Because the LSVT® method is so simplistic and the vocal characteristics between the IPD and Down syndrome population are so similar, it is hypothesized that the LSVT® method will also improve vocal loudness, vocal quality and speech intelligibility characteristics of the Down syndrome population. In this study, vocal quality and speech intelligibility characteristics were measured.
Similar to the Down syndrome population, individuals with Idiopathic Parkinson's Disease (IPD) exhibit characteristics including reduced loudness, a breathy, weak voice, hoarseness, monotone pitch, imprecise articulation and a disordered rate (Darley, Aronson, & Brown, 1969a, 1969b; Logemann, Fisher, Boshes, & Blonsky, 1978; Ramig, Countryman, Thompson & Horii, 1995; Kleinow, Ramig, & Smith, 2001). Furthermore, these individuals show diminished facial expression (Rinn, 1984) reduced coordination of the orofacial system and swallowing disorders (El-Sharkawi, et al, 2002).
In terms of therapy for IPD, LSVT® has been highly beneficial for this population. Cumulative findings document LSVT® training as resulting in increased vocal loudness, vocal quality, motor stability, and enhanced coordination of the respiratory, laryngeal and orofacial systems (Fox et al, 2002). Efficacy data have proven LSVT® beneficial in short and long term, with patients showing increased vocal loudness, quality, and speech intelligibility following treatment (Ramig, Countryman, O'Brien, Hoehn & Thompson, 1996). At the level of speech production, LSVT® has shown to increase respiratory function (Huber, Stathopoulos, Ramig, and Lancaster, 2003), vocal fold adduction (Smith, Ramig, Dromey, Perez & Samandari, 1995), Sound Pressure Level (SPL), sustained vowel phonation, maximum frequency range and lung volume (Kleinow et al, 2001). Additionally, a neuroimaging study conducted by Liotti, et al (2003) showed that the motor and pre-motor cortex of individuals with IPD changed from abnormal activations to normal activations following LSVT® therapy.
In the IPD population, LSVT® has been proven to increase the "duration of sustained vowel phonation, maximum range of fundamental frequency, fundamental frequency variability during speech, and reductions in rate of speech" (Fox, Morrison and Ramig, 2002 p 112). In addition, LSVT® has assisted in the increase of subglottal air pressure and improvement of true vocal fold adduction. (Fox et al, 2002). It is speculated that LSVT® contributes to increased articulatory function, improved coordination of the motor system, including the orofacial system and improvement in swallowing and tongue strength (Fox et al, 2002). As Fox et al (2002) suggest:
LSVT® may affect speech production at two levels. (a) Increased loudness can improve vocal fold closure and enhance the phonatory source consistent with improving the carrier in the classic engineering concept of signal transmission. (b) Increased loudness may stimulate increased effort and coordination across the respiratory, laryngeal, and orofacial systems (p 114).
As mentioned earlier, individuals with Down syndrome exhibit a range of mental abilities, and may have mild or severe cognitive impairments. Similarly, individuals with IPD have a range of cognitive abilities as the diagnosis of IPD carries with it interferences in cognitive processing and reduced working memory capacity. (Dalrymple, Kalders, Jones & Watson, 1994) However, LSVT® is applicable to individuals that have cognitive impairment as the goals and procedures of the training are simple. One simply needs to "talk louder" and "do what I do." (Fox et al, 2002).
Concerns relating to using this type of approach with children with Down syndrome include the potential for vocal hyperfunction. However, the goal of treatment is to train vocal loudness levels that are within normal limits for voice and speech (i.e. not yelling or shouting and remaining under 90 decibels). In studies conducted on individuals with IPD there was no evidence of vocal hyperfunction post-treatment (Smith et al., 1995). Additionally, careful attention and clinical expertise is used with the LSVT® method which serves to teach individuals how to use their voice without danger of vocal abuse.
In summary, children with Down syndrome have speech and voice anomalies which limit functional communication and contribute to negative interpersonal perceptions (Moran, LaBarge & Haynes, 1988). Literature reviews and developments in speech treatment for individuals with IPD provide a solid rationale and framework for testing new treatment options in children with Down syndrome.
This study had two goals. One was to determine if intensive voice treatment (LSVT®) could change the speech system of a child with Down syndrome as evidenced by changes in acoustic measures of voice and speech. The second goal was to determine if there was a therapeutic effect associated with this treatment.
This was analyzed by assessing if listeners preferred post-treatment speech samples over pre-treatment speech samples on the measures of articulation, voice quality and functional communication and if the parent of the experimental subject (S1) perceived changes in their child's speech and voice following the intensive voice treatment.
Participants
Two children with a medical diagnosis of Down syndrome were recruited for this study. The children were matched for age, sex and cognitive level (as determined by school special education reports). The two participants selected for this study were seven year old males with a classification of moderate cognitive disabilities. Additional selection criteria for the subjects included (a) a perceptual speech or voice disorder that was characterized by reduced loudness, loudness variability, monotone, breathy or hoarse, (b) hearing that was within normal limits (whether aided or unaided), (c) no vocal fold pathology, (d) cognitive ability to follow directions and perform the tasks presented, (e) no concomitant factors such as Autism, cleft palate or head injury, (f) stable medications, and (g) no current enrollment in speech therapy with the focus on intelligibility or voice.
The characteristics and severity of speech and voice were determined through parent interview and an initial visit by the investigator to the child's home prior to acceptance into the study. Once both children had been accepted to the study, the participants were randomly assigned as either the experimental subject or the control subject. Once the experimental subject had been chosen, a team consisting of two trained PhD Speech and Language Pathologists (SLP), one Doctoral candidate SLP, and the author, a Master's candidate SLP, visited the experimental subject in his home to conduct an initial interview and assess the child's interests and abilities before beginning therapy.
Subject 1 (S1)
S1 was selected as the experimental subject. This participant was a 7-year, 1 month old male with the diagnosis of Down syndrome. S1 was not on any medication. S1 presented with speech characterized by pharyngeal frication rather than laryngeal phonation. This manner of speaking produced what can best be described as a "palatal fricative phonation" rather than true vocal fold phonation. However, as was reported by the mother of S1, and as was observed by the clinicians, S1 was able to produce true phonation using his vocal folds. The mother of this subject reported that he infrequently spoke in what she called his "big boy voice" (laryngeal phonation) but rather preferred to speak in his "growly voice" (pharyngeal frication).
Perceptual speech and voice characteristics included reduced loudness, monotone pitch, imprecise consonants and a harsh tone. The overall severity of his speech disorder was judged to be severe based on parental report, school report, and observations made during the team home visit. His oral motor function was intact with no motor asymmetry, reduced range of motion or abnormal posturing.
S1 was in an integrated classroom at school with a full time aide and received daily pullout sessions for various therapies (speech and motor therapy). During the time of this study, S1 was in transition between half day classes and full day classes. S1 had been enrolled in early intervention speech therapy since he was an infant. The majority of his speech therapy had been in groups rather than one on one. At the time of the study he was receiving speech therapy three times per week for 45 minutes each time with a focus on language. His mother's biggest concerns included having her son "switch over and vocalize more" by using his vocal folds rather than pharyngeal frication for speech. She reported that he could use his "big boy voice" when angry or happy, but rarely used it in everyday speech.
Subject 2 (S2)
Subject 2 was randomly selected as the control subject. He was a 7-year, one month old male with the diagnosis of Down syndrome. S2 was not on any medication. S2 used true phonation for everyday speech. However, his mother reported that although "he has good vocabulary it is hard for many to understand him, including family." His mother's biggest concern was that people, especially peers, be able to understand him.
Perceptual speech and voice characteristics included imprecise consonants, a hoarse or harsh tone and reduced breath support. The overall severity of his speech disorder was judged to be moderate to severe based on parental report, school report and investigator observation. His oral motor function was intact with no asymmetry, reduced range of motion or abnormal posturing.
S2 attended Kindergarten full time, five days per week during the course of this study. During the first half of the school day he was in a Developmental Learning Center (DLC) and then in an integrated Kindergarten classroom for the second half of the day. S2 received speech therapy in the school setting for an hour a week as well as speech therapy at The Children's Hospital (TCH) of Denver one day a week for an hour. Both speech therapies focused on language and individual sound production. Additionally, S2 received occupational therapy in the school setting one day per week. S2 has been enrolled in speech therapy since two years of age.
Design
The purpose of this study was to examine the effects of an intensive treatment on speech and voice functioning in a child with Down syndrome. A study design appropriate to treatment outcome research was used. As outlined by Robey & Schultz (1998) the initial goal of treatment outcome research is to develop a hypothesis about treatment that can establish the safety of the treatment, is able to be used in later phases, and will demonstrate whether or not subjects improve from the treatment. Because this is a prospective (Phase I) study a single-subject design with control subject was used. In general, Phase I studies are brief, utilize a small sample size, are free of external controls, and are accepting of Type I and Type II errors (Robey & Schultz, 1998). Methods during this initial phase include single-subject experiments and small, single group experiments (Robey & Schultz, 1998).
Procedures
Participant Selection
Participants were selected from an advertisement placed in Denver, Colorado's Mile High Down syndrome Association newsletter (Appendix A). Participants were screened to determine if they met the study criteria. Upon initial contact with the parents or legal guardians a telephone screening questionnaire was completed (Appendix B). This interview confirmed the age, sex and medical diagnosis of the potential participant's child. In addition, information regarding the parent's perceptions of their child's speech and voice difficulties was gathered. If parents were interested in having their child participate in the study, an in-person screening session for the child was scheduled. The screening session included: (a) brief questions about voice and speech to confirm that they have a speech disorder resulting in decreased loudness and decreased intelligibility, (b) an assessment of the child's cognitive ability to determine if the child can follow directions and (c) a hearing screening or parental report of a hearing test within the last 12 months. Additionally, parents were required to obtain doctor's permission for their child to participate in this study.
Study Conditions
Experimental Subject—S1: The experimental subject was enrolled in the LSVT® training protocol. This protocol consisted of three baseline sessions, 16 treatment sessions (four one hour sessions a week for four consecutive weeks) and two post-treatment assessments. The post-treatment assessments occurred the week following completion of the LSVT® training.
Control Subject-S2: The control subject was not enrolled in any unique speech programs during the course of treatment. S2 only attended his usual school and hospital based speech therapies. The control subject was tested during the 3 initial baseline measures and the 2 final post-treatment assessments.
Recording Sessions
Equipment and Set-up
Data collection procedures were the same for all recording sessions (baselines and post-treatments). The duration of each session was 20 to 45 minutes. All data were collected in a sound booth at the National Center for Voice and Speech (NCVS) in Denver, Colorado. For all recording sessions the participants were seated in a stationary office chair with arms. The data were collected by an investigator that was not the treating speech clinician.
Because the subjects had frequent head movements during the session,, they were required to wear a small elastic headband or stocking cap with an omni-directional microphone taped to the band or cap. This allowed for the mouth-to-microphone distance to be kept at a constant 4 inches. To ensure consistency across all recording sessions, a method of calibrating the microphone, as developed by Fox (2002), was used. For calibration, an omni-directional microphone (Audio-technica ATR35s omni-directional lavalier microphone) was taped to a Styrofoam head 4 inches from the head's mouth (the same distance used for the participants). To generate a calibration tone, a Korg Guitar/Bass CA-30 chromatic tuner was placed 4 inches from the omni-directional microphone on the same plane as the Styrofoam head's mouth. A Sound Level Meter (Bruel and Kajer Type 2230) was placed 30 centimeters from the tuner and the generated tone was recorded onto Sony Pro DAT Plus tapes using a Sony RCM-R500 DAT machine. The exact SPL reading was then manually recorded onto each individual subject's protocol sheet. Microphone signals were recorded onto a digital audio tape (DAT) using Sony Pro DAT Plus tapes. A Sony RCM-R500 DAT recorder was used throughout the recording sessions. A calibration tone of 1318.5 Hz sine wave was recorded before the start of each session. For data collection, the microphone analog signal was transmitted through the pre-amplifier (PreSonus BlueTube Stereo Pre-amplifier) and was then recorded by the DAT machine onto the DAT tapes. The analog signal was digitized using Adobe Audition 1.0 via an Audiophile USB Sound Card. All acoustic analysis (i.e. SPL readings) was done using Adobe Audition. In addition, the sessions were audio and video-cassette recorded onto a TDK model DVM60TMEBUSZ5 mini DV tape using a Canon Elura 50 Digital Video Camera. All recording sessions followed the Voice Recording Session Protocol (Appendix C).
Interviews
The control and experimental subjects were not directly interviewed due to their age and cognitive abilities. A brief oral motor examination given by the investigator was completed on each participant prior to the start of the study. The oral motor exam included looking at the child's face at rest, observing their tongue and jaw movements during speech, and looking into their oral cavity to determine if the structures were symmetrical and functional. During the baseline session, the mother of each participant was interviewed and asked questions about her child's speech (Appendix D). The parent was also asked about her child's daily activities and social interactions outside of school. During the post-treatment session the experimental subjects' mother was again interviewed and asked questions regarding what changes she had seen in her child's speech and what her general impressions were of the approach use in the study (Appendix E). The control subject's mother was given this same interview four months following the post treatment session.
Treatment Rating Forms
At the initial post-treatment recording session S1's parent completed a "Treatment Rating Form" (Appendix F). S2's mother completed the same form 4 months post treatment. However, she was asked to complete the questions with regard to how her child's voice was immediately after the post-treatment recording. This form contained 14 questions relating to the parent's reaction to the participant's treatment effects and their general impression of the approach used in treatment. Parents were given a five point rating scale (1—Not at all, 2—Very little, 3—Somewhat, 4—Quite a bit) on which to respond to questions such as "How much do you think your child liked the therapy approach that was used?"
Speech and Voice Tasks
Experimental Tasks: During the recording sessions both participants were asked to perform a variety of speech and voice tasks including 1) Producing maximum duration sustained vowels (say "ah" for as long as you can) (Appendix G) 2) Producing maximum fundamental frequency range (e.g. "say ‘ah' as high as you can" and "say ‘ah' as low as you can") (Appendix H) 3) Diadochokinesis (e.g. "say ‘Puh-Tuh-Kuh' or ‘Patty-Cake' as fast as you can for 15 seconds") (Appendix I) 4) repeating a series of short intelligibility sentences (Appendix J) 5) repeating a series of intelligibility words (Appendix K) and 6) describing a picture from a wordless picture book (Appendix L). In pre and post data collections (recorded sessions) the subjects were coached to "take a deep breath and say ‘ah' for as long as you can". Due to individual differences, the control subject (S2) was able to complete more tasks than the experimental subject (S1). However, for purpose of this study, only the tasks which both participants completed were analyzed and compared. These tasks included producing the maximum duration ‘ah', repeating a series of short intelligibility sentences, repeating a series of intelligibility words, and describing a picture.
The voice tasks (sustained vowels, frequency range) were designed to examine the upper limits of performance for a participant (Kent, Kent, & Rosenbek, 1987). Several repetitions (6-10 trials) were collected at each recording session. The data collector who elicited these tasks asked the subjects to "say ‘ah' for as long as you can" and "do what I do" without coaching them to go loud.
Speaking production tasks were used in perceptual studies to rate any changes in speech at the word, sentence and connected speech level. During the recording sessions each participant was given the Goldman Fristoe test of Articulation (GFTA) to examine speech at the isolated word level. Additionally, to examine speech at the sentence level, the participants were asked to repeat a series of short sentences ("Buy Bobby a puppy," "The potato stew is in the pot," and "The blue spot is on the key"). And, finally, to analyze speech at the connected speech level the participants were asked to describe a picture from the wordless picture book Pancakes for Breakfast by Tomie dePaola. All tasks were audio and video recorded for later blind perceptual analysis.
Data Collectors
To control for bias, all voice-recording sessions (baseline and post) were administered by data collectors and not the experimenter. These individuals were well trained in the experimental protocol. The data collectors were also responsible for conducting the pre and post parent interviews. A separate student clinician assisted the investigator in collecting data manually during the first therapy session in S1's home while the investigator conducted the therapy session. The investigator did not collect data during recording sessions.
Listeners
Five blind raters were recruited from the National Center for Voice and Speech (NCVS) to conduct listener ratings from the pre and post sessions for both subjects. The blind raters were certified Speech and Language Pathologists who are familiar with various vocal traits. The listeners were not familiar with the subjects or the protocol.
Intensive Voice Treatment
The treatment model used in this study was from the LSVT® method (Ramig, & Fox 2002). There were no modifications made to the design of this treatment. However, because children were used for this study, therapy activities were chosen and adapted in order to remain interesting to this population. Treatment consisted of 16 sessions which were an hour in duration and were delivered 4 days a week for 4 consecutive weeks. All of the sessions were conducted in the participant's home with the exception of one which was conducted at the Speech, Language and Hearing Sciences (SLHS) clinic in Boulder, Colorado. This particular session was held at this location due to scheduling conflicts. Any family members present during the therapy sessions were invited to attend as it was felt this would be beneficial for carry over. On two occasions both the older brother and a sister of S1 joined in the sessions and on two occasions only the older brother joined in the sessions.
The original goal of this study was to determine if the traditional LSVT® goal of training an individual to speak loud would transfer to a different population. However, modifications to the original goal were necessary due to S1's vocal characteristics. The experimental subject (S1) spoke using pharyngeal fricative speech production. Due to this vocal characteristic, additional time was spent eliciting laryngeal phonation before intensive voice treatment could be initiated. Despite this additional goal of including laryngeal phonation the overall architecture of intensive voice treatment remained intact. Therefore, the modified goals consisted of an increase in laryngeal phonation prior to focusing on loudness.
Due to S1's voice characteristics the focus of each treatment session was twofold. The primary focus was to produce laryngeal speech and then to increase S1's vocal effort and loudness once laryngeal speech was produced. In LSVT® the cue of "loud" is regularly used to elicit an increase of vocal effort and loudness. In this study, the direct cue to use a "big boy voice" was used. Additionally, suprasegmental language functions such as "I can't hear you," or "say it so I can hear" were used as an indirect elicitation of increased loudness.
The additional goal of laryngeal phonation was incorporated into the beginning of each therapy session. Prior to engaging in the LSVT® protocol, the therapy sessions would begin with activities to induce laryngeal phonation. These activities were designed to elicit laughter which then led to laryngeal phonation. In initial sessions (week 1) S1 needed approximately 10-15 minutes of high intensity laughter before laryngeal phonation was initiated. By week 2 there was less of a need for high intensity stimulation and S1 only required 5-10 minutes of laughter prior to voicing. In weeks 3 and 4 approximately 5 minutes were spent on laughter initiation before beginning the intensive voice treatment. During this time the prompt to use his "Big Boy Voice" was taught as a cue for laryngeal phonation. Therefore, if S1 did not produce adequate voice quality during any of the LSVT® variables the investigator would ask him to use his "Big Boy Voice" in attempts to have S1 use laryngeal phonation. If this cue didn't work the investigator would use a variety of shaping techniques to improve voice quality such as modeling (e.g. "Do what I do"), parallel play (i.e. using appropriate voicing while playing a game in which the participant was to copy the investigators actions), or another short activity that induced laughter.
Following stimulation for laryngeal phonation each day of LSVT® therapy was exactly the same and consisted of three daily variables and one speech loudness drill which lasted for approximately 15 minutes each. To ensure consistency, LSVT® Daily Treatment Forms adapted from the LSVT® training and certification workshop (Ramig, Fox, Will & Halpern 2003) (Appendix L) were used as a guideline for all treatment sessions. Therefore, all treatment sessions followed the same protocol which included (a) maximum duration of sustained "ah" (e.g. "Do what I do" where the clinician would take a deep breath and say "ah" for as long as they could and then have the child repeat it). If the subject did not produce "ah" in the correct manner, the clinician modeled the "ah" (or another sustained vowel such as "oh") for him until he had a steady and stabilized "ah" phonation. (b) Maximum fundamental frequency range (e.g. "go as high/low as you can using your big boy voice") and (c) repeating 10 functional phrases meaningful to the subject (as suggested by the family) 3-5 times each (e.g. "say _____ in your big boy voice"). Additionally, the subject completed a Hierarchical Speech Loudness Drill where he would say words or short phrases using laryngeal phonation (e.g. he would be shown a picture of a car and asked "What is this?" "Tell me in your big boy voice"). This activity began with individual words (e.g. "car") and gradually increased to short phrases by the end of treatment (e.g. "Go fast car"). The purpose of these exercises was to shape good voice quality while increasing the strength and endurance necessary for adequate respiratory and laryngeal coordination used in speech production.
All exercises included repeated trials (i.e. a minimum of 10 repetitions of each training task), while incorporating sensory augmentation (cueing increased vocal effort and loudness) and sensory awareness (e.g. "Did you feel your voice? Did you hear how that sounded?"). Homework exercises, which included the treatment tasks of sustained ah's, high/low ah's, and functional phrases were asked to be completed on a daily basis. Carry-over exercises such as "Use your ‘big boy' voice to say ‘Good morning' to your teacher" were also given.
The family was also asked to complete daily homework (Appendix N). The parents were asked to have S1 practice one time a day for 5-10 minutes on the days he received treatment, and twice a day for 5-10 minutes on the days he didn't receive treatment. The homework consisted of a short version of the treatment where S1 was to complete 3 sets of 10 "ah's" and the hierarchical speech loudness exercises.
Data Analysis
Data Preparation and Digitizing Procedures
All acoustic data recordings were reviewed and screened for problematic samples. Problems included recording failure (one recording session for each participant) and the data collector talking at the same time as the subject on microphone signals (approximately 3-5 samples from each participant). Samples from the DAT tapes were digitized at 44.1 kHz using the acoustic analysis program Adobe Audition 1.0 installed on a 2004 Dell computer with a Pentium 4 processor. Each recording session was saved via Adobe Audition and then specific tasks (e.g. sustained vowel, individual words from the Goldman Fristoe, repeated sentences and picture description) were digitized and saved in individual wave files for further analysis. The calibration tone for each recording session was analyzed for decibels of sound pressure level (dB SPL) using Adobe Audition.
Acoustic Analysis
Due to the voice characteristics of S1, acoustic analysis of fundamental frequency (Fo), and sound pressure level decibels (dB SPL) was not carried out As mentioned previously, S1 spoke using pharyngeal frication rather than laryngeal phonation which resulted in samples that were not able to be acoustically analyzed. For this reason, acoustic analysis of S1 and S2 were not conducted.
Sustained phonation
For each sustained vowel sample from all pre and post recording sessions, Adobe Audition 1.0 was used to display the acoustic waveform. From these samples the duration of each sustained "ah" was measured. The three longest pre and post samples for S1 and S2 were selected and the duration times were recorded.
Auditory-Perceptual Analysis (Investigator)
The investigator listened to all recorded pre and post samples for S1 and S2. S1 displayed 3 main voicing characteristics across the pre and post recordings. These consisted of pharyngeal frication, laryngeal whispering and laryngeal voicing. The characteristic of pharyngeal frication was categorized separately as this characteristic is produced in a different place (pharynx). Due to this deviant speech characteristic of S1, the investigator looked for an increase in laryngeal speech production (whispering and/or voicing) and a decrease in pharyngeal frication from pre to post measures. To complete this, the investigator reviewed all recorded tracks (GFTA, picture description, intelligibility sentences, sustained "ah") from S1's pre and post recording sessions and coded them according to the manner of voicing used (pharyngeal frication, laryngeal whispering or laryngeal phonation). Percentages were derived by tallying and dividing the results according to manner of voicing. Graphs were made from the results for visual analysis. Voicing was judged to be better if laryngeal phonation and laryngeal whispering increased from pre to post and if pharyngeal frication decreased from pre to post.
S2 had typical laryngeal phonation throughout all pre and post recording sessions. Therefore, no auditory-perceptual analysis by the investigator was necessary for S2.
Auditory-Perceptual Analysis (Listener Task)
Five experienced listeners were selected to complete a pair-comparison listening task (Fox, 2002). All five listeners were certified speech-language pathologists who had extensive training and experience in the area of motor speech disorders and voice. Combinations of pre and post samples from three tasks (Goldman Fristoe test of Articulation [GFTA], picture description and sustained "ah") were used. The sentence repetition task was not analyzed by listeners. Rather, the picture description task was chosen for analysis because it involves spontaneous language which is more representative of everyday speech. The listeners were asked to rate a total of 50 sample pairs (25 for each participant). The samples were presented in the same order for each listener starting with the GFTA, followed by the picture description and ending with sustained "ah." The first eight tracks (4 pairs from each participant) included selections from the GFTA that were used as a listening exercise and were not rated. The listeners were not informed that the first 8 tracks would not be rated. For each task the order of presentation of words within each pair (e.g. pre to post or post to pre) and the order of presentation of the 50 pairs (e.g. S1 or S2) were randomized.
For the GFTA samples, 11 pairs of words from the pre and post recording sessions for each participant were selected. To measure for listener reliability, three of these pairs were randomly selected and repeated for each participant. Therefore, the total number of pair presentations per participant was 8.
The picture description samples consisted of 4 word pairs from the pre and post recording sessions for each participant. Although some recording sessions contained connected speech, all pre and post samples were analyzed and individual words were selected and matched from pre and post sessions (e.g. the word ‘pancake' was identified in a pre sample and then the same word was identified in a post session and presented as a matched pair). No tasks to rate listener reliability were used in this section.
The 3 best "ah" samples for each participant were selected and matched for pre and post samples. To rate listener reliability all 3 samples were reversed and repeated (e.g. If the first ‘ah' presentation for S1 was post then pre, the second presentation of the same set would be pre then post). Therefore, there was a total of 6 "ah" presentation for each participant, consisting of 3 pairs and 3 reversals of these pairs. A total of 30 tracks were listener rated (15 for each participant).
All five listeners were given a CD which contained the 50 tracks they were to rate. Listeners were able to complete the ratings on their own time and in their own office seated comfortably in a chair at a desk with a computer and speakers. The listeners were able to control all acoustic measures (e.g. volume, location of speakers). Listeners were asked to listen to a pair of speech samples and to rate which sample they "preferred" for the following variables: articulation, voice quality, and functional communication. A General Information Sheet (Appendix O) outlining the definitions of these variables were provided to each listener. Listeners were asked to mark on a rating form which sample they "preferred" Sample 1, Sample 2 or No Preference for each variable (articulation, voice quality and functional communication), (Appendix P-R). Listeners used the Windows Media Player program to listen to the CD.
Listeners were allowed to adjust the volume control on the speakers to a loudness level that was comfortable to them. Listeners were instructed to complete one variable at a time (i.e. to listen to the CD and record their preference for all 50 variables based on articulation before moving onto another variable) and not to listen to a track more than two times for each variable. Listeners were allowed to take breaks at anytime. The listening task took approximately 30-60 minutes to complete.
For each of the three perceptual characteristics (articulation, voice quality, and functional communication) and each of the three tasks (GFTA, picture description and sustained "ah") weighted choices for preference were made per participant. The GFTA task had a total of 40 choices (5 listeners x 8 pairs), the picture description task had a total of 20 choices (5 listeners x 4 pairs) and the sustained "ah" task had a total of 15 choices (5 listeners x 3 pairs). For each of these categories, tabulations were made for the number of times a speech sample from a pre session or post session or a choice of "no preference" was selected. Percentage scores for preference of speech samples were calculated by dividing the frequency of preference of a given category by the total number of choices for that variable (e.g. 30 choices for Post samples/40 possible choices= 75% preference for Post speech samples). The percentage scores for all three perceptual variables were graphed for visual analysis.
The six repeated pairs per participant (three from the GFTA, three from the sustained "ah") were analyzed for agreements in choice of preference from the first presentation of a pair to the repeated presentation. Agreement ratings were tallied and summed. A percentage of within listener agreement was calculated from the summed values and reported as an index of within-listener reliability. Across the five listeners, within listener reliability ranged from 77-88% for the GFTA, and 83-94% for the sustained "ah's." Together these ratings averaged from 82-88% for within listener reliability.
Analysis of Parent Perceptual Ratings
Analysis of the "Treatment Rating Form" involved tabulating the parents' rating responses (1—Not at all, 2—Very little, 3—Somewhat, 4—Quite a bit) to each of the 14 questions. The responses were graphed for visual analysis. Comments from the parents' written post-treatment interview were reviewed.
Determination of Treatment Effects
In single subject designs the evaluation of treatment effects is based primarily on visual inspection of data (McReynolds & Kearns, 1983). The process of visual inspection involves looking for a change of direction (trends), the steepness of the direction change (slope) and the frequency of occurrence (level) in data (McReynolds, et al, 1983). As Cynthia Fox outlined in her dissertation, Intensive Voice Treatment for Chidren with Spastic Cerebral Palsy (2002) these observations can be used to evaluate the "...stability of a baseline performance, overlap between scores in adjacent phases, changes in trend between phases, and changes in level between phases" (p 61). However, the standards for evaluating treatment effects from the trend, slope and level remain loosely defined (McReynolds & Kearns, 1983). Therefore, changes across phases must be great enough to disallow for ambiguous analysis during visual inspection. For this reason, visually observed trends were considered strong if accompanied by a change in level of 20% or more.
In this study participant data for investigator and listener preference ratings as well as parent perceptual ratings were displayed graphically. Changes in level (e.g. the percentage of preference) between study phases (pre and post) were visually examined for trends (McReynolds & Kearns, 1983). Trends that had a 20% or more change in level were considered to be indicative of a treatment effect.
Data for each subject (S1 and S2) are presented individually. S1's voicing characteristics demonstrated a preference for using pharyngeal frication rather than vocal-fold vibration when phonating. Due to these voicing characteristics the Fundamental Frequency (Fø) and sound pressure level (SPL) were not calculated as they were not acoustically measurable. Therefore, the dependent variables consisted of time unit measures (duration of longest sustained "ah") and perceptual measures (investigator and listener ratings).
Data for S1
Sustained Frication (Phonation) (Three Longest Vowels)
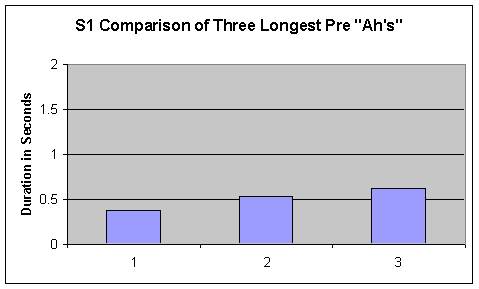
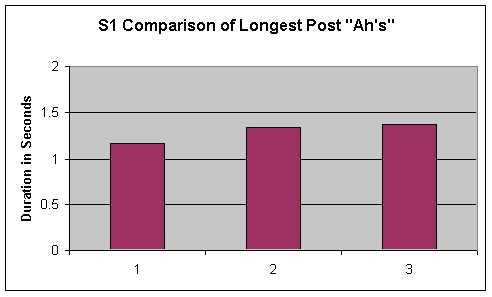
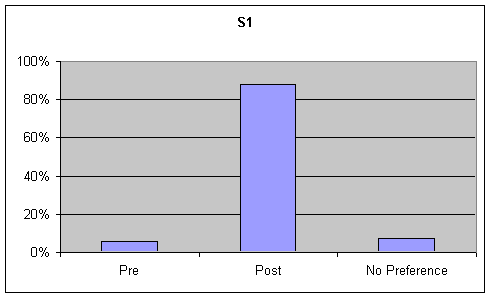
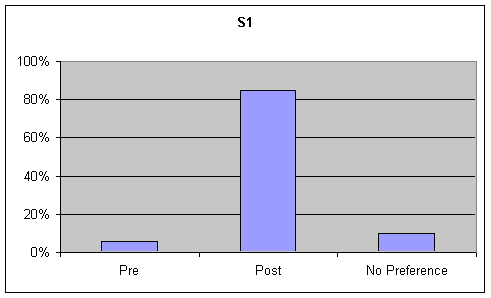
During this recorded task S1 produced only pharyngeal frication. Therefore, the level measured was not sustained ‘phonation' but rather sustained ‘frication.' Duration of frication length from the three longest sustained "ah's" for P1 (pre and post measures) are displayed in the first two graphs of Figure1. Visual inspection of sustained frication length revealed an upward trend of 50% or greater from pre to post measures.
Investigator Ratings
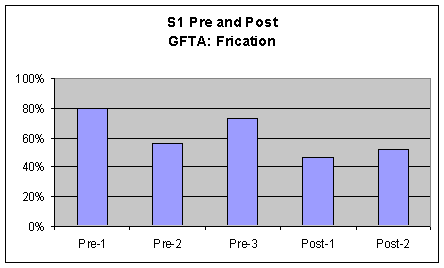
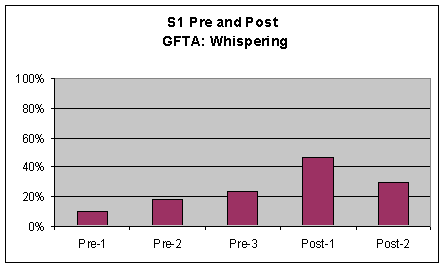
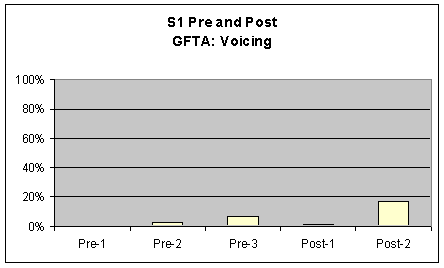
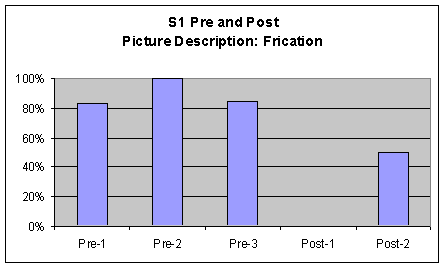
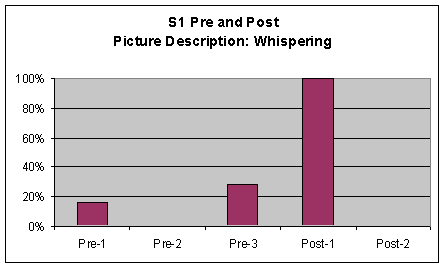
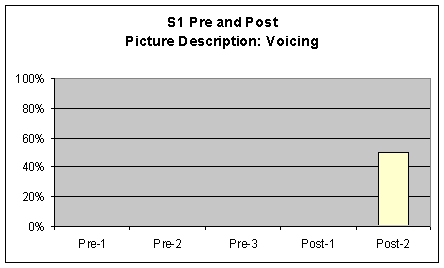
Goldman Fristoe Test of Articulation (GFTA) For the GFTA, perceptual ratings of S1's voice characteristics were marked and tallied by the investigator based on percentage of words produced with pharyngeal frication or laryngeal vibration (whispering and voicing). Words were counted as voiced if S1 voiced at least one phoneme in the word. A comparison chart was made to graph these results from S1's pre-1, 2, and 3 and post 1 and 2 sessions. The graph is included in the first three graphs of Figure 3. Visual inspection of the data from this task revealed several strong upward movements (i.e., accompanied by a 20% or more increase or decrease). There was a 20% or greater decrease in frication from pre to post measures. Additionally, there was strong upward movement (20%) for whispering from pre to post measures. In terms of voicing S1 there was upward movement of voiced words in the post measures of the GFTA, however, this increase was not accompanied by a 20% or greater increase and was therefore not significant. Although this difference was not significant, it should be noted that in S1's pre measures the voicing was on phonemes only whereas in his post measures the voicing consisted of whole words.
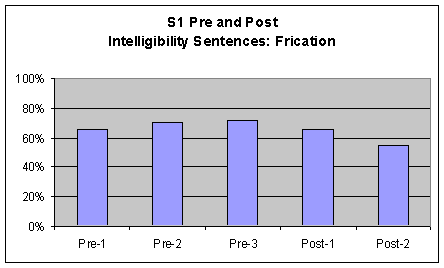
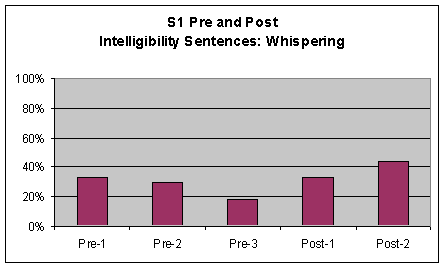
Intelligibility Sentences Perceptual ratings of S1's voice characteristics during the intelligibility sentences were also marked and tallied by the investigator based on percentage of words produced with pharyngeal frication and laryngeal vibration (whispering and voicing). As in the previous task, words were counted as voiced if S1 voiced at least one phoneme in the word. A comparison chart was made to graph these results from S1's pre-1, 2, and 3 and post 1 and 2 sessions. The chart is included in the first three graphs of Figure 4. Although this was designed as a sentence repetition task, S1 was not able to reproduce the entire sentence. Therefore, rather than saying "Buy Bobby a puppy; The potato stew is in the pot; and The blue spot is on the key" S1 was instructed to say "puppy, potato and pot" respectively.
Visual inspection of the data from this task revealed no strong movement (accompanied by a 20% or greater change in behavior). There was a decrease in frication from pre to post measures; however, this change was less than 20% and therefore was not significant. Additionally, there was upward movement (less than 20%) for whispering from pre to post measures, which were only significant (greater than 20%) between the pre-3 and post-2 measure. In terms of voicing S1 did not produce any voiced words in either post-measure although he did produced some voiced sounds during the pre-3 measure. The difference in voicing from pre to post was not accompanied by a change of 20% or greater and therefore indicated no change.
Picture Description Picture description perceptual ratings of S1's voice characteristics were marked and tallied by the investigator in the same manner as the previous tasks. Words were counted as voiced if S1 voiced at least one phoneme in the word. A comparison chart was made to graph these results from S1's pre-1, 2, and 3 and post 1 and 2 sessions. The chart is included in as the first three graphs of Figure 5. Visual inspection of the data from this task revealed strong movement (greater than 20%) across all measures. There was a greater than 20% derease in pharyngeal frication from pre to post measures and a greater than 60% increase of laryngeal whispering from pre to post measures. Finally S1 produced more laryngeal voicing in post measures with more than a 40% increase from pre to post measures.
Listener Ratings
Percentages of listener ratings for preference of speech samples taken at pre and post sessions are displayed in figures 6-13.
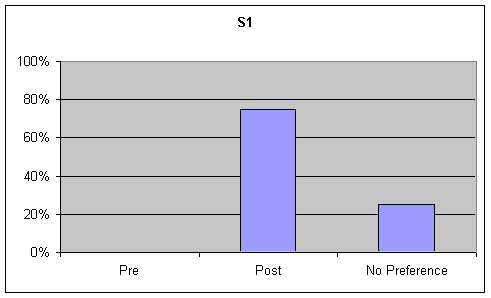
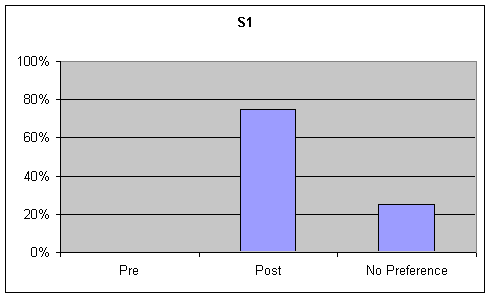
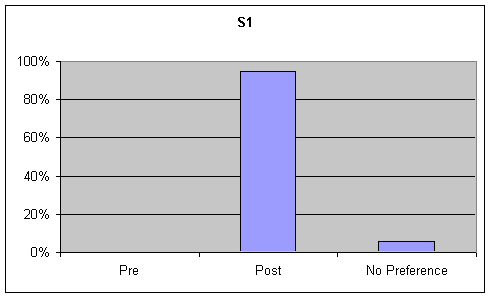
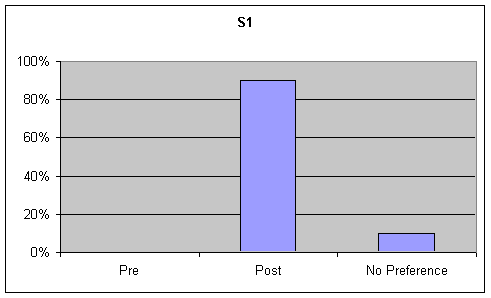
Functional Communication: Visual inspection of the data identified strong trends ranging from 50% to 90% for preference of post speech samples over base samples for functional communication on the GFTA and picture description task. Although listeners were asked to rate functional communication on the sustained "ah" task, this information was not analyzed as functional communication is not a component of sustained "ah" phonation. These tables are presented in the first graph of Figures 6-7.
Articulation: Visual inspection of the data identified strong trends accompanied by a change of 20% or greater for preference of post speech samples over base samples for articulation. Although listeners were asked to rate articulation on the sustained "ah" task, this information was not analyzed as articulation is not a component of sustained "ah" phonation. These figures are presented in the first graph of Figures 8-9.
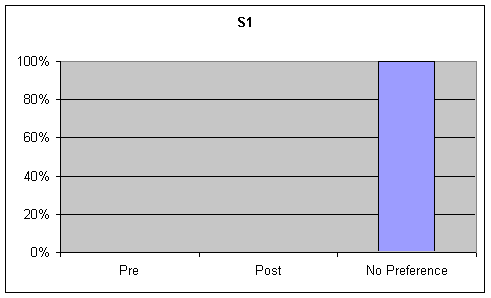
Voice Quality: Visual inspection of the data identified strong trends of 20% or greater for preference of post speech samples over base samples for voice quality on the GFTA and picture description task. On the sustained "ah" task there was a 100% trend for "no preference". These tables are presented in the first graph of Figures 11-13.
Parent Rating Forms
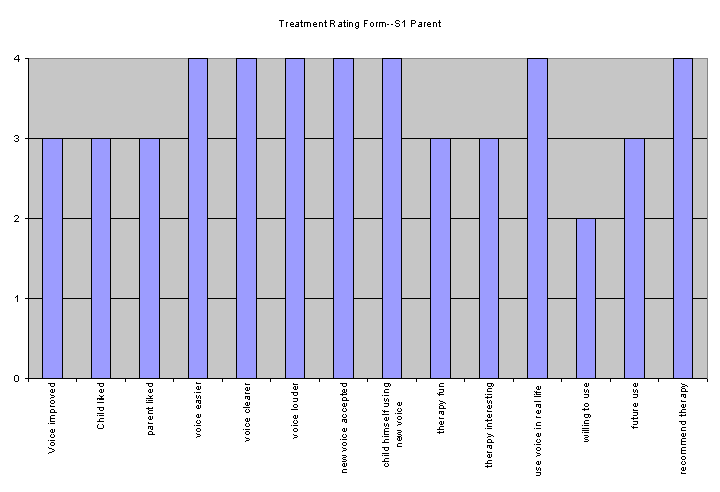
Parent perceptual ratings are displayed in Figure 14. The Treatment Rating Form was given to S1's parent during the first post-session. Visual inspection of the data identified positive results (a score of 3 or higher on a 4 point scale) for 13 of 14 characteristics. The only characteristic that received a negative rating was "willingness to use" where the mother reported S1 had "very little" willingness to use the techniques outside of therapy.
On the Parental Post-Treatment questionnaire, the mother of S1 reported that she noted changes in his voice "during therapy primarily," that there "was/is some carryover," and that his speech therapist reported he "is vocalizing a little more." She also reported that this type of therapy is "...definitely worth considering. I would like to see [S1] continue." However, she also noted that he wasn't "particularly motivated to help people understand him, but he will ‘perform' for a desired reward." When asked whether or not people still have a hard time understanding S1, his mother replied "yes" and that "he still primarily uses a growl-type [pharyngeal frication] voice or whisper." Overall the comments from the post-treatment questionnaire were positive and demonstrated parental awareness of a beneficial change in S1's voice.
Summary of results for S1
Results indicate a slight improvement in increased vowel length (sustained "ah") from pre to post measures although this trend was not accompanied by a 20% or greater change. The speech task measures (GFTA, intelligibility sentences, and picture description) demonstrated a slight movement (less than 20%) from pharyngeal frication to laryngeal vibration for all vocal characteristics. This movement includes a decrease in pharyngeal frication and an increase in laryngeal phonation from pre to post measures. For the listener rated acoustic measures S1 demonstrated a strong trend (greater than 20%) for improvement in all areas including functional communication, voice and articulation on the GFTA and picture description tasks. Listener rated acoustic measure for sustained "ah" phonation demonstrated a strong trend (greater than 20%) for "no preference." Overall parent impressions of S1's response to treatment and impressions of the treatment technique were favorable.
Although S1 did not demonstrate a strong movement from pharyngeal frication to laryngeal phonation in all pre and post measures the investigator would like to note that any change was seen as favorable as the vocal characteristics and interpersonal qualities S1 presented with were challenging. In addition to the deviant vocal characteristics which made it more difficult to target the goals of LSVT®, S1 was often resistant to therapy and presented with various behavior challenges. Despite these challenges, S1 was able to demonstrate a shift in his motor system from pharyngeal frication to laryngeal vibration through increased whispering and voicing. Therefore, these transformations in S1's system were seen as positive, even if some changes were not indicative of a 20% or greater shift.
Data for S2
Because S2 had appropriate phonation for all pre and post measures, investigator perceptual ratings were not completed for this subject. Therefore, the only characteristics analyzed for S2 include sustained phonation, listener perceptual ratings and parental reports.
Sustained Phonation (Three Longest Vowels)
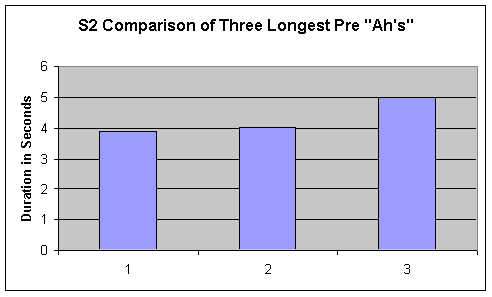
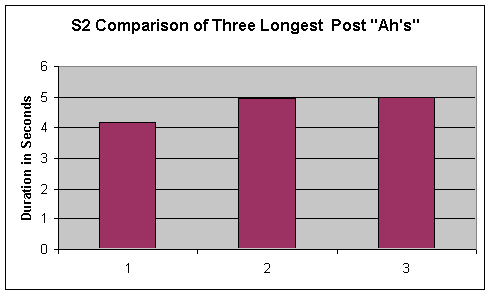
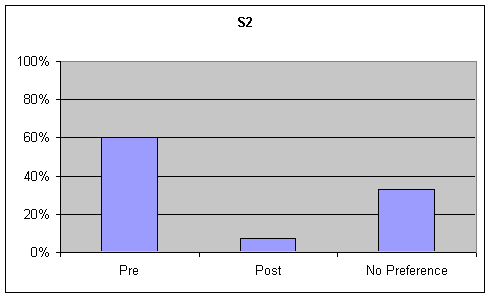
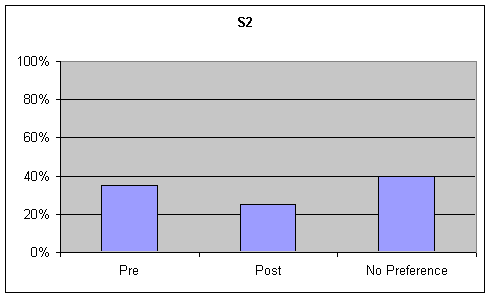
Duration of vowel length from the three longest sustained vowels for P2 are displayed in the first two graphs of Figure2. Visual inspection of sustained phonation length revealed no trends or changes in phonation length from pre to post.
Listener Ratings
Percentage of listener ratings for preference of speech samples from pre to post are presented in the second graph of Figures 6-13.
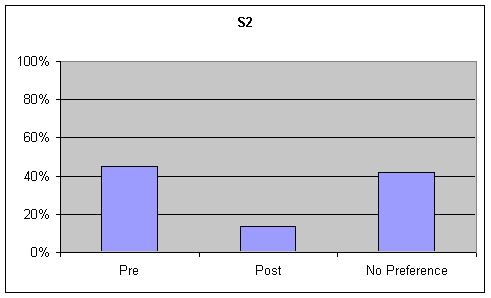
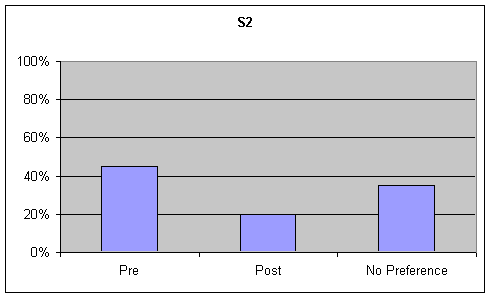
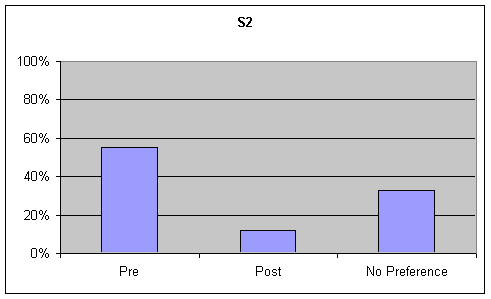
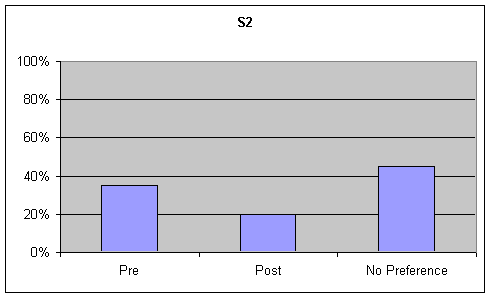
Functional Communication: Visual inspection of the data revealed a strong trend (20% or greater) for preference of the pre-speech samples over post-speech samples or "no preference" on the GFTA task, while no trend (no ratings had a difference of 20% or greater) was noted for the picture description. Although listeners were asked to rate functional communication on the sustained "ah" task, this information was not analyzed as functional communication is not a component of sustained "ah" phonation. These tables are presented in the second graph of Figures 6-7.
Articulation: Visual inspection of the data identified no strong trends of 20% or greater for S2's articulation. Listeners selected "no preference" and "pre" in near equal amounts for the GFTA and picture description tasks. Although listeners were asked to rate articulation on the sustained "ah" task, this information was not analyzed as articulation is not a component of sustained "ah" phonation. These tables are presented in the second graph of Figures 9-10.
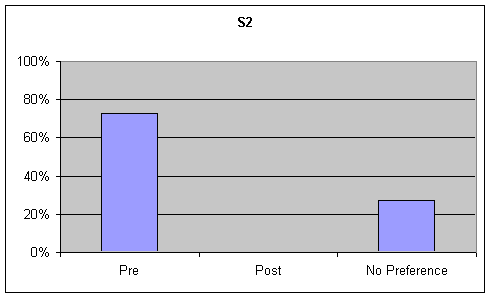
Voice Quality: Visual inspection of the data identified a strong trend for pre-speech samples to be preferred over post-speech samples or "no preference" for the GFTA and sustained "ah" tasks. However, on the picture description task there was a slight trend (less than 20%) for no preference, although this trend was not considered strong. These tables are presented in the second graph of Figures 11-13.
Parent Perceptual Ratings
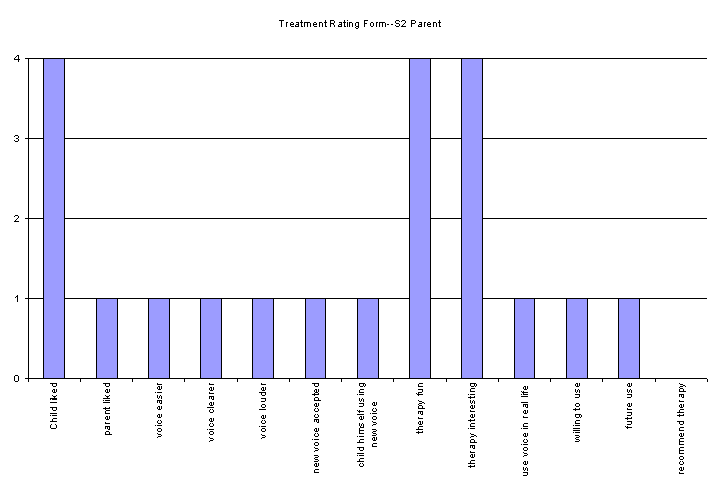
S2's mother completed a Parent Perceptual Rating form and a Post-Treatment Questionnaire. Results from the Parent Perceptual Rating is displayed as a graph in table 15. S2's mother rated his enjoyment and interest in therapy high (4 out of 4) because "he really liked coming to [NCVS]." However, all other measures were given the lowest ratings (1 out of 4). S2's mother reported that there were no changes in his voice from pre to post measures.
Summary of Results for S2
Results indicate a general trend in preference for S2's pre speech samples. It is not known why this trend was evident as all pre and post speech samples were selected, recorded and analyzed in an identical fashion. The mother of S2 did not report any adverse changes in her child's speech from pre to post measures. However, it was noted that allergies have an adverse effect on S2's voice which may have contributed to listeners preferring his pre-measure voice.
This original purpose of this study was to examine the effects of an intensive voice treatment program in a child with Down syndrome. As a result of S1's pharyngeal frication the study also incorporated the goal of increasing laryngeal vibration in the experimental subject. The study posed two questions: Will intensive voice treatment (LSVT®) change speech production in a child with Down syndrome? And; if speech does change, is there a positive therapeutic effect? In addition to these two original questions, a third was added once treatment began. (S1). The experimental subject who received treatment (S1) demonstrated positive changes post-treatment. These changes were noted by listener preference for post speech samples and by investigator analysis of pre and post speech characteristics. The experimental subject also demonstrated a shift from pharyngeal frication to laryngeal phonation as observed in the investigator analysis. There was minimal change in the control subject (S2) over time. Together, these findings suggest that the speech production of the experimental subject was changed and that a therapeutic effect was present following intensive voice therapy. The implications of these findings and directions for future research are discussed below.
Changes in the Speech System
Although this thesis set out to determine if changes occurred in the speech production of a child with Down syndrome, the answer was not able to be properly determined. As explained previously, S1's everyday speech consisted of pharyngeal frication rather than laryngeal vibration. Because of this speech production characteristic, speech samples were not able to be analyzed acoustically. Fundamental Frequency (Fo), Harmonics to Noise Ratio (HNR), and Sound Pressure Level (SPL) were not useful measures of treatment related change. . However, the investigator analyzed perceptual ratings which did show a substantial increase in S1's use of laryngeal vibration for speech in the post speech samples.
The one measurable change in S1's speech production from pre to post measures was that of sustained "ah" length. In this measure S1 increased his "ah" duration by .8 seconds—from a pre average (3 longest "ah's") of .5 seconds, to a post average (3 longest "ah's") of 1.3 seconds. Even though S1 used pharyngeal frication during this task, his duration of "ah" production was longer, suggesting that changes did occur in S1's speech motor system. As Kleinow, Smith and Ramig (2001) report from a study with Idiopathic Parkinson's Disease (IPD) patients: "Lung volume excursion during speech increases significantly following therapy. At the phonatory/laryngeal level, significant improvement in pre-and post-treatment variables such as duration of sustained vowel phonation...have been reported" (p 1042).
Notes taken from the investigators therapy sessions show a similar picture. In initial sessions S1 was not willing or able to produce a sustained laryngeal "ah" or individual words. However, as the sessions continued S1 would produce laryngeal "ah's" that lasted up to 5 seconds in duration. During these sessions the investigator would frequently change the task so "ah" was not the target sound (e.g. "Do what I do: Say ‘whoo-whoo'"). Changing the task in this manner kept S1 engaged and allowed him to complete the task within a play activity. By the 5th session S1 was not only producing sustained laryngeal "ah's" but he was also producing 4-5 word sentences with laryngeal vibration.
Evidence of a Therapeutic Effect
To determine if changes in the motor speech system resulted in a therapeutic effect, listeners rated their preference for speech samples from both participants (S1 and S2) across pre and post recording sessions. Overall, listener ratings revealed strong preferences for post-treatment speech samples over pre-treatments samples on nearly all perceptual variables for the experimental subject (S1). Listener ratings for the control subject, S2, did not show strong preferences for post-speech samples. However, on some of the variables listeners did show a preference for S2's pre-speech samples. Although it is not known why this happened (all recording sessions followed the same protocol and there were no reported anomalies with S2's voice) it was noted that S2 sounded more "energetic" in the pre speech samples.
Parent interviews and Treatment Rating Forms were consistent with the findings from the investigators perceptual ratings and the listener's perceptual ratings. S1's parent reported that they have seen "...more rapid progress and interest in [S1] with this therapy than any previous treatments (language, articulation, oral motor, core strengthening)..." and that "This therapy has been more effective than any other for voice and volume." S2's parent reported that they have seen "no change" in S2's voice during the course of the study, although he did enjoy coming to NCVS for the recording sessions.
General Comments on the Treatment Model
The treatment approach used in this study differs from traditional speech treatment approaches for children with Down syndrome. The approach used in this study adheres to ideas, studies and suggestions outlined by various Down syndrome experts, as summarized below. A study by Pryce (1994) acknowledges the poor articulatory abilities of this population and states that "...far more emphasis needs to be placed on the problems of initiating voice. Ideally, this should be incorporated into early therapy packages so that an awareness of the problem and procedures to remediate it can be started...Therapy techniques for increasing vocal efficiency need to be devised" (p 110). In terms of intervention, Rosin and Swift (1999) state that "as of 1999 there are no intervention programs or guidelines to assist speech-language pathologists in developing integrated approaches to meet both the speech intelligibility and language communication needs of this population" (p 133). Rosin and Swift (1999) continue to suggest remediation strategies that incorporate visual feedback and functional phrases. In this chapter, Rosin and Swift (1999) suggest that Melodic intonation therapy (MIT) may be useful for the Down syndrome population because of the hierarchical difficulty levels. Furthermore, Leddy and Gill (1999) suggest using therapy techniques that bring attention to the individual's difficulty and then using that person's words as cues for them to speak more clearly. Examples include the following: "‘Change your talking,' ‘Speak clearly,' Use all your words,' and ‘Say it so I can understand you'" (p 207). Leddy and Gill (1999) also suggest using a more general approach that is not specific to individual speech sounds, but rather encompasses the way one talks (e.g. to open you mouth wider when speaking).
The treatment model used in this study covered many of the aforementioned aspects. LSVT® is comprised of a hierarchy of tasks that utilize functional phrases, is not speech sound specific, focuses on initiating and shaping the voice, and promotes vocal efficiency. The LSVT® method attempts to push participants beyond their current level of comfort and functioning using intensive voice therapy which incorporates high effort, repeated trials and sensory awareness/sensory augmentation training (Fox, 2002). The treatment focused only on voice tasks to improve speech. The direction to use a "big boy voice" appeared cognitively easy for S1 to understand, however, he would not consistently produce a "big boy voice" on command. During the times S1 would not produce a "big boy voice" on command the investigator would illicit a laugh from S1 (which consistently led to production of the target voice) and then identify this voice as his "big boy voice." In discussing with S1's mother his understanding or possible lack of understanding for producing a "big boy voice" it was felt that he understood the command but preferred to speak using palatal frication.
The intensive treatment program was accepted by S1 and his family, with the exception of the daily homework. S1's mother reported that he would put "...his head in his lap when I [tried] to work with him. His siblings [would] work on "ah's" with him in the car." And that "He [was] more eager to perform for his siblings." S1's mother also reported that "It was difficult initially to watch him be pushed beyond what he wanted, but it paid off and he began to look forward to seeing [the investigator]. It was great to hear him vocalize." On occasion S1 would become frustrated with the investigator and would refuse to produce any sounds. During these times (one-half of 4 sessions) the investigator would find a way to engage S1 in laughter or would play a game independently until S1 joined on his own volition.
S1 was able to follow cues for multiple repetitions, and would increase his vocal output during repeated practice trials. S1 performed tasks best when modeled by the investigator or a sibling, but was also able to produce laryngeal phonation of increasing intensity and duration without a model. Cues for sensory awareness (i.e. "Do you feel your voice," "That's your ‘big boy voice'!") went largely unnoticed by the subject. However, he would imitate the investigator by placing his hand over his larynx and attempt phonation.
Overall, S1's parents reported a favorable response to the treatment. His parents reported that they felt he had fun during treatment, his voice was clearer, louder, and easier during treatment and that they would recommend therapy this therapy to other parents of children with Down syndrome. S1's parent did report that she would like to "...explore ways to generalize what he is doing during the LSVT® therapy sessions...Maybe even [merge] therapy into everyday situations as feasible (i.e. having [the school] therapist help elicit good voicing in [S1's] classroom at school so he is learning and using in context." The investigator agrees that carryover is essential for facilitating maximum treatment gains into daily living.
Study Critiques and Future Directions
This study represented a Phase 1 research design in order to examine potential therapeutic effects associated with an intensive treatment approach for children with Down syndrome (Robey & Schultz, 1998). A single subject design was sued and therefore results of this study cannot be generalized to the population of children with Down syndrome. The results of this study revealed that the treated subject (S1) was able to make improvements on several measures and that treatment was favored by the family. These findings provide support to further examine the effects of intensive voice therapy for children with Down syndrome.
Several design flaws in this study were noted including the protocol for administering post-parental questionnaires, data collection tasks, and value of homework completion. The post-parental questionnaires were not initially administered to the family of the control subject (S2). Because the investigator was not involved in the recording sessions (to decrease bias) it was not properly communicated to the data collectors that parental questionnaires should be distributed to both families.
S1 was inconsistent in responding to the directive of using his "big boy voice" and therefore required cueing (i.e. elicitation of laughter) it would have been helpful to elicit cued speech in the pre-recording sessions and again in the post-recording sessions in order to compare potential changes in cued speech at post-treatment sessions. Therefore, data collection tasks could have been enhanced if procedures for cueing S1 to laugh were used in pre and post measures.
Finally, although S1's parents were instructed to complete homework each night this task was not reliably completed or enforced. It may have been beneficial if the investigator took more time to stress the importance of this task. Homework is one of the essential tasks of the LSVT® method as it designed to "provide additional practice of treatment tasks, help patient become comfortable with use of louder voice and establish a routine for homework practice" (Ramig & Fox, 2003, p 2-43). Homework is also designed to act as a carry-over for using the new voice in novel situations. However, if it is not completed then carry-over may become more difficult.
Regarding the treatment model used in this study, this population may require additional external supports (e.g. training of the clients school speech therapist) to maximize carry over of the treatment techniques outside of the therapy sessions. To complete this, instructing people the child sees out side of the home setting (e.g. teachers, school aides, coaches, classmates and other therapists) to cue the child to use his "big boy voice" would provide additional support in a variety of contexts. Furthermore, this population may also require therapy of a longer duration (e.g. 2 months instead of 1). As Leddy and Gill (1999) suggest "The treatment that we provided to adults with Down syndrome lasted for many months. It may have taken 24 months of weekly therapy to help one individual reach a goal, whereas it may have taken another individual 30 months of twice-per-week intervention to reach a similar goal...Large-scale investigations are needed to identify which interventions are most effective for improving speech and language skills..." (p 213).
Additionally, data for this study was collected in a sound booth in a novel setting. This method for data collection is not necessarily representative of the subject's best abilities as the setting was unusual and atypical for normal speech production. Therefore, future work should evaluate treatment related change in a range of environments. For a more representative sample of speech and language changes in this population following treatment, pre and post recording sessions should be conducted in the same setting as the therapy. In order to test for carry-over recording sessions can be conducted in a variety of environments including home, school and the sound booth.
Summary and Conclusions
The purpose of this study was to explore the effects of an intensive speech treatment on changing the speech motor system of children with Down syndrome and to determine if a therapeutic effect was evident. Measures related to duration of sustained phonation, auditory-perceptual analysis of speech samples and treatment ratings by parents of participants were used for this study. The participant who received treatment (S1) demonstrated a marked change (greater than 20%) in performance on more than one measure (length of phonation, auditory-perceptual ratings) from pre to post speech samples. The parents of S1 reported improved perceptions of several speech and voice characteristics and had an overall favorable impression of the treatment approach used. The subject who did not receive treatment (S2) was listener-rated as having a better voice in pre measures. However, this trend was not strong and was split between a preference for pre-samples and no preference between samples. These findings suggest that the treatment succeeded in changing the speech patterns of S1 and demonstrated a therapeutic effect.
Future studies need to be conducted with a varied length of treatment (e.g. 2 months versus 1) in order to determine if an increased length of therapy results in more carry-over. Additionally, conducting a study with a 6 month follow-up recording session may serve to determine if the treatment effects are lasting. Finally, studies need to be conducted on a larger scale that employs more children with Down syndrome so generalization of treatment outcomes can be determined for this population.
Batshaw, M.L., (Ed). (2002). Children with disabilities. Washington, D.C.: Paul H Brookes.
Benda, C. (1969). Down's Syndrome: Mongolism and Its Management. New York: Grune and Stratton.
Blachard, I. (1964). Speech patterns and etiology in mental retardation. American Journal of Mental Deficiency, 68, 613-617.
Buckley, S. (1993). Developing the speech and language skills of teenagers with Down's syndrome. Down's Syndrome: Research and Practice, 1, (63-71).
Chapman, R.S., Raining-Bird KRS, Schwartz, SE, (1991) Language skills of children and adolescents with Down syndrome: I, Comprehension. Journal of Speech and Hearing Research, 34 253-260.
Chapman, R.S. (1995). Language development in children and adolescents with Down syndrome. In P. Fletcher & B. MacWhinney (Eds.), The Handbook of Child Language (p 641-663). Cambridge, England: Basil Blackwell.
Chapman, R.S. (1997). Language development in children and adolescents with Down syndrome. Down's Syndrome Research and Practice, 1, 63-71.
Cossu, G., Rossini, F., & Marshall, J.C. (1993). When reading is acquired but phonemic awareness is not: A study of literacy in Down's syndrome. Cognition, 46, 129-138.
Dalrymple, A.J.C., Jones, R.S., Kalders, A.S., & Watson, R.W. (1994). A central exectutive deficit in patients with Parkinson's disease. Journal of Neuology, Neurosurgery, and Psychiatry, 57, 360-367.
Darley, F.L., Aronson, A.E., & Brown, J.R. (1969a). Differential diagnosis patterns of dysarthria. Journal of Speech and Hearing Research, 12, 246-249.
Darley, F.L., Aronson, A.E., & Brown, J.R. (1969b). Clusters of deviant speech dimensions in the dysarthrias. Journal of Speech and Hearing Research, 12, 462-496.
Dodd, B. (1976). A comparison of the phonological system of mental age matched normal, severely subnormal and Down's syndrome children. British Journal of Disorders of Communication, 11, 27-42.
El-Sharkawi, A., Baum, S., Logemann, J., Pauloski, B., Pawlas, A., Rademaker, A., Ramig, L., Smith, C., & Werner, C. (2002). Swallowing and voice effects of Lee Silverman Voice Treatment: A pilot study. Journal of Neurology, Neuropsychiatry, and Psychiatry, 72 (1), 31-36.
Fowler, A. (1995). Linguistic variability in persons with Down syndrome: Research and implications. In L. Nadel & D. Rosenthal (Eds.), Down syndrome: Living and Learning in the Community (p 121-131). New York: Wiley-Liss.
Fox, C. (2002). Intensive Voice Treatment for Children with Spastic Cerebral Palsy, Unpublished doctoral dissertation, The University of Arizona, Phoenix.
Fox, C., Morrison, C., & Ramig, L. (2002). Current perspectives on the Lee Silverman Voice Treatment (LSVT) for individuals with Idiopathic Parkinson Disease. American Journal of Speech Language Pathology, 11, 111-123.
Hamilton, C. (1993). Investigation of the articulatory patterns of young adults with Down syndrome using electropalatography. Down Syndrome Research and Practice, 1(1), 15-28
Huber, J.E., Stathopoulos, E.T., Ramig, L.O., and Lancaster, S.L. (2003). Respiratory function and variability in individuals with Parkinson Disease: Pre- and post-Lee Silverman Voice Treatment. Journal of Medical Speech-Language Pathology, 11(4), 185-201.
Jung, J.H. (1989). Genetic syndromes in communication disorders, Boston/Toronto: College-Hill Press.
Kent, R.D., Kent, J.F., & Rosenbeck, J.C. (1987). Maximum performance tests of speech production. Journal of Speech and Hearing Disorders, 52, 367-387.
Kleinow, J., Ramig, L.O., & Smith, A. (2001). Speech motor stability in IPD: Effects of rate and loudness manipulations. Journal of Speech, Language, and Hearing Research, 44, 1041-1051.
Kumin, L (1994). Intelligibility of speech in children with Down syndrome in natural settings: Parent's perspective. Perceptual and Motor Skills, 78(1), 307-313.
Leddy, M., (1999). The biological bases of speech in people with Down syndrome. In Miller, JF, Leddy, M., & Leavitt, J.F. (Eds.), Improving the Communication of People with Down Syndrome (p 61-80). Baltimore, Maryland: Paul H Brookes.
Leddy, M., & Gill, G. (1999). Enhancing the speech and language skills of adults with Down syndrome. In Miller, JF, Leddy, M., & Leavitt, J.F. (Eds.), Improving the Communication of People with Down Syndrome (p 205-214). Baltimore, Maryland: Paul H Brookes.
Liotti, M., Cook, M.S., Fox, P.T., Ingham, J.C., Ingham, R.J., New, P., Ramig, L.O., & Vogel, D. (2003, February). Hypotonia in Parkinson's disease: Neural correlates of voice treatment revealed by PET. Neurology, (1), 432-440.
Logeman, J.A., Fisher, H.B., Boshes, B., & Blonsky, E.R., (1978). Frequency and coocurrence of vocal tract dysfunctions in the speech of a large sample of Parkinson patients. Journal of Speech and Hearing Disorders, 43, 47-57.
McReynolds, L.B. & Kearns, K.P. (1983). Single-subject experimental designs in communicative disorders. Baltimore: University Park Press.
Miller, J.F. (1987). Language and communication characteristics of children with Down syndrome. In S.M. Pueschel, C. Tingey, J.E. Rynders, A.C. Crocker, & D.M. Crutcher (Eds). New perspectives on Down syndrome (p 233-262). Baltimore, Maryland: Paul H Brookes.
Miller, J.F. (1988). The developmental asynchrony of language development in children with Down syndrome. In L. Nadel (Ed.), The psychobiology of Down syndrome (p 167-198). Cambridge, Massachusetts: MIT Press.
Miller, J.F., Leddy, M., Miolo, G., & Sedey, A. (1995). The development of early language skills in children with Down syndrome. In L. Nadel & D. Rosenthal (Eds.), Down Syndrome: Living and Learning in the Community (p 115-120). New York: Wiley-Liss.
Miller J.F., & Leddy, M. (1998) Down syndrome: The impact of speech production on language development. In R. Paul (Ed.) Communication and language intervention series: Exploring the speech language connection (Vol 8) (163-177). Baltimore, Maryland: Paul H Brookes.
Miller, JF (1999). Profiles of language development in children with Down syndrome. In Miller, JF, Leddy, M., & Leavitt, J.F. (Eds.), Improving the Communication of People with Down Syndrome (p 11-39). Baltimore, Maryland: Paul H Brookes.
Miller, JF, & Leddy, M. (1999). Verbal fluency, speech intelligibility, and communicative effectiveness. In Miller, JF, Leddy, M., & Leavitt, J.F. (Eds.), Improving the Communication of People with Down Syndrome (p 81-92). Baltimore, Maryland: Paul H Brookes.
Montague, J.C., Brown, W.S., & Hollien, H. (1974). Vocal fundamental frequency characteristics of institutionalized mongoloids. American Journal of Mental Deficiency, 78, 414-418.
Moran, M., LaBarge, J. & Haynes, W. (1988). Effect of voice quality on adult's perceptions of Down's syndrome children. Folia Phoniatr, 40, 157-161.
Pentz, A., & Gilbert, H. (1983). Relation of selected acoustical parameters and perceptual ratings to voice quality of Down syndrome children. American Journal of Mental Deficiency, 88 (2), 203-210.
Pryce, M. (1994). The voice of people with Down's syndrome: An EMG biofeedback study. Down Syndrome Research and Practice, 2 (3), 106-111.
Ramig, L., Countryman, S., Horii, Y., & Thompson, L. (1995). A comparison of two forms of intensive speech treatment for Parkinson disease. Journal of Speech and Hearing Research, 38, 1232-1251.
Ramig, L., Countryman, S., Hoehn, M., O'Brien, C., & Thompson, L. (1996). Intensive speech treatment for patients with Parkinson disease: Short and long term comparison of two techniques. Neurology, 47 1496-1504.
Ramig, L., Fox, C., Will, L. & Halpern, A. (2003, January). Lee Silverman Voice Treatment (LSVT®) Training and Certification Workshop, 2003. Workshop conducted in Boulder, Colorado.
Rinn, W. (1984). The neuropsychological of facial expression: A review of the neurological and psychological mechanisms for producing facial expressions. Psychological Bulletin, 95 52-77.
Robey, R.R., & Schultz, M.C. (1998). A model for conducting clinical-outcome research: An adaptation of the standard protocol for use in aphasiology. Aphasiology, 12, 787-810.
Rosin, M.M., Swift, E. Bless, D., & Vetter, D.K. (1988). Communication profiles of adolescents with Down syndrome. Journal of Childhood Communication Disorders, 12, 49-64.
Rosin, P., & Swift, E. (1999). Communication Interventions: Improving the speech intelligibility of children with Down syndrome. In Miller, JF, Leddy, M., & Leavitt, J.F. (Eds.), Improving the Communication of People with Down Syndrome (p 133-160). Baltimore, Maryland: Paul H Brookes.
Schlanger, B.B. & Gottsleben, R.H. (1957). Analysis of speech defects among the institutionalized mentally retarded. Journal of Speech and Hearing Disorders, 22, 98-104.
Shepperdson, B. (1994). Attainments in reading and number of teenagers and young adults with Down's syndrome. Down's Syndrome: Research and Practice, 2, 97-101.
Smith, M.E., Ramig, L.O., Dromey, C., Perez, K., & Samandari, R. (1995). Intensive voice treatment in Parkinson's disease: Laryngostroboscopic findings. Journal of the Acoustical Society of America, 85, 285-312.
Spender, Q., Stein, J., Cave, D., Reilly, E., & Reilly, S., (1995). Impaired oral-motor function in children with Down's syndrome: A study of three twin pairs. European Journal of Disorders of Communication, 30 77-87.
West, R., Ansberry, M., & Carr, A. (1957). The Rehabilitation of Speech: A textbook of diagnostic and connective procedures based upon a critical study of speech disorders (3rd edition). New York: Harper
Figure 1. Pre and post comparisons of the 3 longest sustained "ah" durations for S1.
Pre measures are presented in the first Figure, post measures are presented in the second Figure.
Figure 2. Pre and post comparisons of the 3 longest sustained "ah" durations for S2.
Pre measures are presented in the first Figure, post measures are presented in the second Figure.
Figure 3. Comparison charts of S1's pre and post voice measures (frication, whispering, voicing) for the Goldman Fristoe Test of Articulation (GFTA). The desired effect is a decrease in frication and an increase in both whispering and voicing.
Figure 4. Comparison charts of S1's pre and post voice measures (frication, whispering, voicing) for the intelligibility sentences. The desired effect is a decrease in frication and an increase in both whispering and voicing.
Figure 5.Comparison charts of S1's pre and post voice measures (frication, whispering, voicing) for the picture description. The desired effect is a decrease in frication and an increase in both whispering and voicing.
Figure 6, Figure 1. Percentage of listener ratings for S1's "Functional Communication" on the Goldman Fristoe Test of Articulation (GFTA)
Figure 6, Figure 2. Percentage of listener ratings for S2's "Functional Communication" on the Goldman Fristoe Test of Articulation (GFTA)
Figure 7, Figure 1. Percentage of listener ratings for S1's "Functional Communication" on the picture description task
Figure 7, Figure 2. Percentage of listener ratings for S2's "Functional Communication" on the picture description task
Figure 8, Figure 1. Percentage of listener ratings for S1's "Articulation" on the GFTA.
Figure 8, Figure 2. Percentage of listener ratings for S2's "Articulation" on the GFTA.
Figure 9, Figure 1. Percentage of listener ratings for S1's "Articulation" on the picture description task.
Figure 9, Figure 2. Percentage of listener ratings for S2's "Articulation" on the picture description task.
Figure 10, Figure 1. Percentage of listener ratings for S1's "Voice quality" on the GFTA.
Figure 10, Figure 2. Percentage of listener ratings for S2's "Voice quality" on the GFTA.
Figure 11, Figure 1. Percentage of listener ratings for S1's "Voice quality" on the picture description task.
Figure 11, Figure 2. Percentage of listener ratings for S2's "Voice quality" on the picture description task.
Figure 12, Figure 1. Percentage of listener ratings for S1's "Voice quality" on the sustained "ah" task.
Figure 12, Figure 2. Percentage of listener ratings for S2's "Voice quality" on the sustained "ah" task.
Figure 13. Treatment Rating Form: S1 parent post survey.
Figure 14. Treatment Rating Form: S2 parent post survey.